Early check on Byte Latent Transformation (Dec 2024)
he following is likely of interest to Data Science people, ML dev folks and some academics. I published the code in my personal research repo. I am not affiliated with Meta’s AI research. It may be that my understanding is not correct. If that is, please let me know. I will correct my assumptions, give attribution etc.
This is an independent blog post without any monetization, written by an ML nerd. Enjoy.

Byte Level Transformation (BLT) is new research by Meta (formerly Facebook). It’s a method for pre-processing text by breaking it down into smaller fragments, similar to syllables but even on byte groups.
What is Byte Latent Transformation?
Just a couple of days ago, researchers from Meta published AI / ML research with code. The paper is named “Byte Latent Transformer: Patches Scale Better Than Tokens”. These “Patches” are like text fragments or “segments” or “Patches”:
Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it.
One key advantage of Byte Latent Transformation (BLT) is, that it works without a fixed vocabulary. Based on byte entropy, space maybe or Byte-Pair Encoding with BLT Patches. All with the goal to divide the input well enough, so that subsequent Machine Learning processes can be enabled. BLT promises to provide the means to increase model inference. Let’s take a look.
Byte-Pair Encoding vs Byte Latent Transformation
BPE (Byte-Pair Encoding) is a known standard in Natural Language Processing (NLP). It works robustly, has decent performance, and therefore it’s the go-to pre-processor for Transformer Networks nowadays. It’s used by OpenAI and Anthropic, most notably.
Transformer Networks are en vogue and the basis of modern models like GPT-4, Haiku and Gemini most notably. Or Mistral, Llama or Cohere. Since the publication “Attention is all you need” (which brought forth BERT) that is.
BPE Tokenization:
--------------------------------------------------
Full sequence token IDs: [1, 15043, 29892, 445, 338, 263, 1243, 29889, 2]
Full decoded text: Hello, this is a test.
Tokens and their decoded values:
--------------------------------------------------
Position 0: ID 1 -> ''
Position 1: ID 15043 -> 'Hello'
Position 2: ID 29892 -> ','
Position 3: ID 445 -> 'this'
Position 4: ID 338 -> 'is'
Position 5: ID 263 -> 'a'
Position 6: ID 1243 -> 'test'
Position 7: ID 29889 -> '.'
Position 8: ID 2 -> ''
BLT uses a Local Decoder and a Local Encoder Layer, and applies grouping. An extra hierarchy, that’s transformation and not tokenization.

Source: Byte Latent Transformer: Patches Scale Better Than Tokens (Figure 2, page 3)
From bottom to top: it applies a Local Encoder, then the Transformer works on the small groups (n-gram Embeddings), and there is a Cross-Attention approach. Generally speaking: it retains access to byte-level information but builds Patches. These Patches are like tokens for the Latent Transformer. And if you want a vector, you pass the sequence of patches to this model. This model generates the vector representation.
Byte Patcher initialized successfully!
Byte Patcher test results:
Original data length: 71 bytes
Batch shape: torch.Size([1, 71])
Number of patches: 9
Patch 0: Length=8, Data=b'Hello Wo'
Patch 1: Length=8, Data=b'rld! Thi'
Patch 2: Length=8, Data=b's is som'
Patch 3: Length=8, Data=b'e test b'
Patch 4: Length=8, Data=b'inary da'
Patch 5: Length=8, Data=b'ta with '
Patch 6: Length=8, Data=b'varying '
Patch 7: Length=8, Data=b'entropy '
Patch 8: Length=7, Data=b'levels.'
The idea is dare et impero, typical Computer Science.
For these Patches, you need a different vectorization / embedding model. Models like Longformer or Linformer usually get trained wit BPE tokens, and not with BLT Patches. Thankfuklly, Meta’s publication includes an Embedding model.
BLT Embedding generation - hands on research
Let’s check out some Python code which I generated to make use of Meta’s new research. You can find my entire code in the GitHub repository.
It uses 1024 dimensions and the meta-llama/Llama-2-7 tokenizer
It imports the BLT code (revision bcc039b) from a sub-folder
The configuration is typical to Transformer Models with Attention models
It uses half-mode (Float / FP16) which is enough for most (if not all) Transformer Network architectures on CUDA.
I have not been successful using the cross-attention mode (I think there is a bug).
I used the Byte-Level Patcher (not the space or Byte-Pair Encoding mode)
This uses Rotary and Positional Encoding techniques (these are new Natural Language Processing techniques in Transformer Models to improve Embeddings). Cutting-edge stuff my friends.
▶ Read also on GitHub
def create_blt_model(checkpoint_path=None, model_dim=1024, verbose=True):
"""
Create a BLT model with the specified configuration.
Args:
checkpoint_path (str, optional): Path to a model checkpoint to load.
model_dim (int): Model dimension. Default is 1024.
verbose (bool): Whether to print model details.
Returns:
ByteLatentTransformer: The initialized model.
"""
from torch import nn
from bytelatent.model.utils import downsample
import torch
from bytelatent.model.blt import ByteLatentTransformer, ByteLatentTransformerArgs
# Calculate dependent parameters
n_heads = model_dim // 64 # Keep head_dim=64 constant
if verbose:
print(f"Initializing model with:")
print(f"- Model dimension: {model_dim}")
print(f"- Number of heads: {n_heads}")
vocab_size = model_dim # Set vocab_size to model_dim to get desired output dimension
max_seqlen = 10_000
args = ByteLatentTransformerArgs(
dim=model_dim, # Model's internal dimension
n_layers=12,
n_heads=n_heads, # Scales with dim to maintain head_dim=64
vocab_size=vocab_size, # Set vocab_size to model_dim to get desired output dimension
patch_size=4,
patching_mode="bpe",
downsampling_by_pooling="avg",
max_seqlen=max_seqlen,
max_length=max_seqlen,
max_encoder_seq_length=max_seqlen,
weight_tying=True,
sliding_window=None,
cross_attn_encoder=False,
cross_attn_decoder=False,
cross_attn_k=4,
cross_attn_window_encoder=None,
cross_attn_window_decoder=None,
cross_attn_use_flex_attention=False,
encoder_hash_byte_group_size=[4],
encoder_hash_byte_group_vocab=256,
encoder_hash_byte_group_nb_functions=4,
encoder_enable_byte_ngrams=False,
data_loader_patching=False,
patching_threshold=0.5,
patching_threshold_add=0.0,
monotonicity=False,
max_patch_length=None,
init_std_factor="disabled",
init_base_std=0.02,
head_dim=64, # Keep constant
rope_theta=10000.0,
use_rope=True,
dropout=0.0,
norm_eps=1e-5,
pm_size=0,
efficient_attn="fmha",
use_local_encoder_transformer=True,
patch_only_encoder=False,
patch_only_decoder=False,
share_encoder_decoder_emb=False,
cross_attn_nheads=n_heads, # Scales with n_heads
cross_attn_all_layers_encoder=False,
cross_attn_all_layers_decoder=False,
cross_attn_init_by_pooling=False,
entropy_model_checkpoint_dir=None
)
try:
# Create model
if verbose:
print("Creating model...")
if torch.cuda.is_available():
device = "cuda"
dtype = torch.float16
else:
device = "cpu"
dtype = torch.float32
model = ByteLatentTransformer(args)
# Add output projection to get desired dimension
model.output_proj = nn.Linear(vocab_size, model_dim).to(device=device, dtype=dtype)
model = model.to(device=device, dtype=dtype)
model.device = device # Store device for later use
if verbose:
print(f"Model initialized successfully on {device}")
return model
except Exception as e:
if verbose:
print(f"Error creating model: {e}")
import traceback
traceback.print_exc()
raise
Creating 1024-dimensional BLT vector embeddings takes a lot of computation. But it’s actually comparatively fast, on par with Linformer. Which already scales linearly for longer token sequences.

Embedding generation on a local test system (CUDA, GTX 1650). An A100 (in Google Colab) is much faster, of course. This GPU has controlled excess heat. The test system uses Windows 11 and CUDA 12.x. CUDA is optimized to perform on Windows and Linux. Of course, we all love the Linux dev experience. But sometimes with Nvidia software, it’s not the best choice. Let’s be honest.
Hardware planing - GPU memory is a key consideration for Transformer Networks
Byte Latent Transformer pre-processing benefits from GPU computing. In the following, this is limited to Nvidia’s CUDA, which is the de-facto standard in ML. It is possible to run this model in FP16 (half mode) instead of FP32. Numerical stability shouldn’t be an issue for Transformer Networks, as previously mentioned. In their architecture, Transformer Networks aren’t precise classifiers and Neural Networks in general do not rely on floating-point precision; for the most part.
If I understand Meta’s implementation correctly, the ByteLatentTransformer needs the following memory:
ByteLatentTransformer: 60 million parameters * 2 Bytes (FP16) = 120 MB
+ AdamW optimizer: 720 MB (for training)
+ Activation memory is based on the sequence length: roughly 30 MB
+ 15% CUDA kernels and workspace = 256 MB
+ fragmentation buffer = 200 MB
= roughly 1,5 GB or training or 400 MB for inference only. These are experience values. Not a science.
The conclusion is that we can host this on a consumer-grade GPU that doesn’t exhibit a lot of excess heat. Of course, the models are designed for A100s, but that’s not a limiting factor here.
As a notice: if you look at the ByteLatentTransformer dimension hierarchy and the information flow of the related Patching and dimensions, you realize that the model is designed to transform the byte patches to higher-level vectors. You are not limited to a vocabulary of 256 + special tokens (based on bytes) or to 512 dimensions. That’s not explicitly mentioned in the paper, but I used 1024 dimensions. This is because I want to compare the embeddings regarding the preserved features and the resulting cluster-ability. In production, you don’t always benefit from more dimensions, especially not when you use Deep Learning. That is evident by the results below.
Hardware planing II - throughput analysis of Byte Latent Transformer vs. Byte-Pair Encoding with Linformer Embeddings
The BLT code comes with a pre-trained model, which we can test on a consumer-grade GPU to create Embeddings. I also tested it with 256 and 512 dimensions.
Looking at the implementation (and not the paper) I see a 3-stage architecture:
Local Encoder: Processes raw bytes as inputs. This is where the BLT is similar to BPE in so far, that there is no vocabulary approach. This is different from pre-Transformer NLP approaches like TF-IDF, which used vocabulary-based approaches
Global Transformer: Processing of Patch-level representations. These sequences can be 6–8 times longer than BPE sequences, which can create issues when you define a vector projection. Many transformer models have exponentially growing memory and computation requirements with increasing sequence lengths. Linformer does not, but you need to be aware of the limiting factors indicated by the Patch-based transformation step.
Local Decoder: decodes back to byte-level predictions. Not in focus in the following.
The Embedding is based on the vectorized Patches, and since it’s a Transformer Network architecture, the last tensor will hold the result (hidden state). For Linformer this is very similar.
Basic performance comparison
Initializing BLT model with:
- Model dimension: 1024
- Number of heads: 16
Creating model...
Model initialized successfully on cuda
=== BLT Embedding Analysis ===
Input Text: "Hello, this is a test."
=== TOKEN Embeddings ===
Shape: torch.Size([1, 31, 1024])
• Batch size: 1
• Sequence length: 31
• Embedding dimension: 1024
• Parameters: 31,744
• Share of total: 33.33%
...
=== Overall Statistics ===
Total parameters across all embeddings: 95,232
Execution time: 1.95 seconds
Initializing Linformer model...
Using GPU: NVIDIA GeForce GTX 1650
Execution time: 3.18 seconds
The data (vectorized messages from a Microsoft tool named Sysmon.) is not the ideal case. The message are filtered, and do not contain timestamps and other “noise”. The data is actually from another project. It’s also on Kaggle. You can find the test code I used above on GitHub. The speed is relative, and on Google Colab or AWS EC2 with attached GPUs you will see improvements. The use-cases for this sort of dataset can be related to security monitoring, log-analysis or digital forensics. ML here transfers the security problem into a search problem.
The message length and the resulting tokens are fit for benchmark tests. In the test above, the BLT embeddings computation is about twice as fast, compared to the BPE approach with Linformer. But it’s more complex because you have to move an additional model to the GPU. The design of the BLT Transformer is made on A100 or newer models. That is understandable, as it is a research level implementation. Everyone uses the big GPUs.
Complexity like this should pay off: with better inference and more use cases. Generally, the expectation is, that GPU processing capacity will be cheap in the near future. But it will never be free.
Tests with the two Open-Source Deep Learning Embeddings
To understand the benefits, I defined tests to inspect the vector similarity (Cosine) and the resulting clusters of the features from two Deep Learning models:
BPE tokens and Linformer (1024 dimensions). The pre-trained model on GitHub works well, and we can use LinformerLM.
BLT Byte Patches and Byte Level Transformer (1024 dimensions). Here we also use the new pre-trained model from the publication.
Initially, both embeddings get generated from the same message and stored in a DuckDB index. This is beneficial because we can use SQL queries with the results and use the data to generate the right model metrics. And SQL is king in Data Science.
DuckDB supports some vector operations, but it’s not as good as FAISS or Milvus even. It’s sufficient for the following tests. Using a Polars or Pandas dataframe could lead to memory exhaustion because they don’t support memory spilling to disk. Dataframes are the standard-way for in-memory table operations in Data-Science. But they aren’t good for persistence and large files which exceed the memory capacity.
Test 1: Value and Cosine Similarity distribution
In Machine Learning and NLP, Cosine Similarity is a preferred vector similarity metric over the Euclidean Distance.
The calculation is in the Jupyter Notebook in the GitHub repository.

Byte-Pair Encoding with LinformerLM on the left, and Byte Latent Transformations with Byte Patches and the Transformer on the right

Byte-Pair Encoding with LinformerLM on the left, and Byte Latent Transformations with Byte Patches and the Transformer on the right.
This suggests that BPE embeddings of different log messages are almost orthogonal to each other. Very low similarity between different messages, which might indicate that BPE is treating each message as very distinct. The BLT curve shows a strong peak around 0.92. This suggests that BLT embeddings capture more semantic similarities between messages. High baseline similarity might indicate that BLT recognizes common patterns in log messages.
This is interesting: we know that the domain-specific data contains a very similar message corpus. But Byte Latent Transformation has captured the differences well. The distribution is much better.
Test 2: Silhouette Score and clustering analysis with KMeans
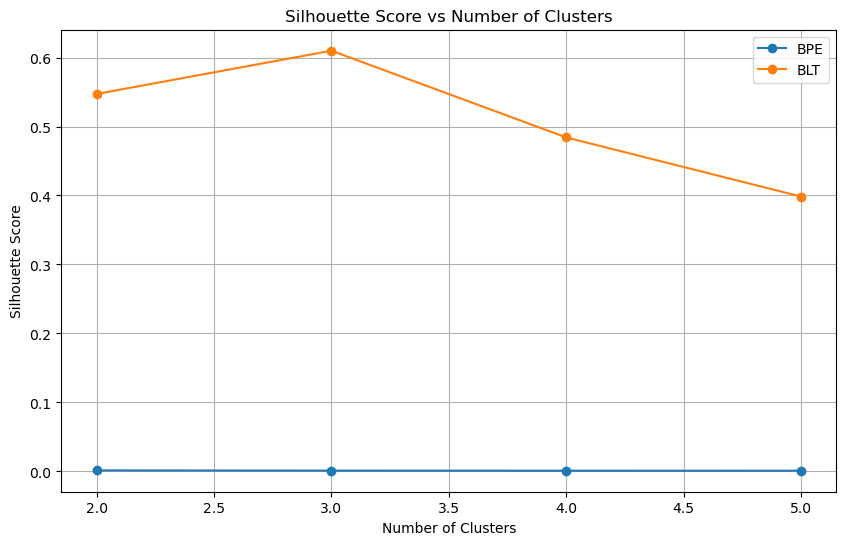
The Silhouette Score (range -1 to 1) seems much better for Byte Latent Transformers (BLT). The clustering is possible, seems to be work best with 3 clusters here. The flat line for the BPE would indicate that more profound analysis is necessary, maybe related to scale sensitivity.
Test 2: Principal Component Analysis

Left Plot (Cumulative Explained Variance):
BLT (red line): Reaches ~95% variance rapidly (within first few components), is almost flat after that, indicating most information is captured in first few dimensions. Very efficient compression seems possible.
BPE (blue line): Grows much more slowly. Needs many more components to explain same amount of variance. Much more distributed information across dimensions. Almost scattered completely.
Right Plot (Scree Plot - First 20 Components):
BLT (red line): Very high variance in first component (~0.75). Sharp drop after that. Shows most information is in the first few components.
BPE (blue line): Much lower variance per component. More evenly distributed. Each component contributes a similarly small amount.
Interpretation of the results
BLT embeddings are highly compressible - most information is in the first few dimensions
BPE embeddings are more distributed - need many more dimensions to capture the same information
This explains earlier clustering results:
BLT's concentrated information made clustering more effective
BPE's distributed nature made clustering harder
And for classification, the features from Deep Learning models should be easy to cluster. In my opinion, Byte Latent Transformation can be very useful for Information Security use cases. Bring it into log analysis and Digital Forensics, together with agentic implementations? Who knows?
Summary
This (pseudo-)scientific blog post did exemplify how to compare embeddings and models with domain-specific text data. It didn’t go into the domain modeling and the relevant use cases by intention.
BLT Patches are new, and the potential inference gains seem exceptional (Byte Patches)
I am confident that it can pay off in Byte-Pair Encoding mode as well. Here the emphasis was on Byte Latent Transformation vs. Byte-Pair Encoding.
For classification tasks with complex text patterns, Byte Latent Transformations seems to be the way to go. Both models, the BLT Transformer and Linformer are from Meta AI research. It’s always worth spending a couple of hours on their R&D. I did have good results with Linformer on the same dataset, but used it differently. ML is grindy.
Next topics for Because Security AI research:
I will look into at Modal for remote method invocation to offload GPU computation. Then I can run my GPU lab on my dedicated server instance, which doesn’t have a GPU. But I don’t want to send the data to a third party (for the InfoSec domain). Maybe that’s possible. A potential difference to Google Colab is, that I may have less setup overhead with the Python environments. With Mamba or Conda this is uncomfortable to say the least.
Agentic development with LangChain for Data Science tasks seems interesting. I can see that data exploration and SQL statement generation can be done by an agent LLM integration. I am interested in verification steps to ensure that the LLMs do not inject or exfiltrate data (accidentally). The concept I have in mind here is similar to GreenSQL, which is a “SQL firewall”. This would need a reimplementation because it’s 15 years old. But an agentic reimplementation is a possibility.
I am also interested in how Zero Trust Network Access (ZTNA) with TLS Inspection for Data Leak Prevention (DLP) can work with AI integrations. An index DLP can prevent sharing classified data with AI systems, even if the users are unaware. In Retrieval Augmented Generation (RAG) integrations, which agents like Cursor or Windsurf have, an entire folder gets indexed and transmitted. That’s like sending a ZIP file with the classified data.
Currently, I am working on integrating Chronos on Open High Low Close Volume (OHLCV) trading data. AutoGluon makes this easier. But the feature-engineering is key, especially for these models. pytimetk seems to be a possible way to simplify this. I don’t expect good predictions because even lagged features lack an intrinsic value representation. But that could also be added based on factors, like various Cash Flows or equities or seasons for Futures. Algorithmic trading can also become agentic. However, domain knowledge is key. As always in ML.
Many ideas. :)